
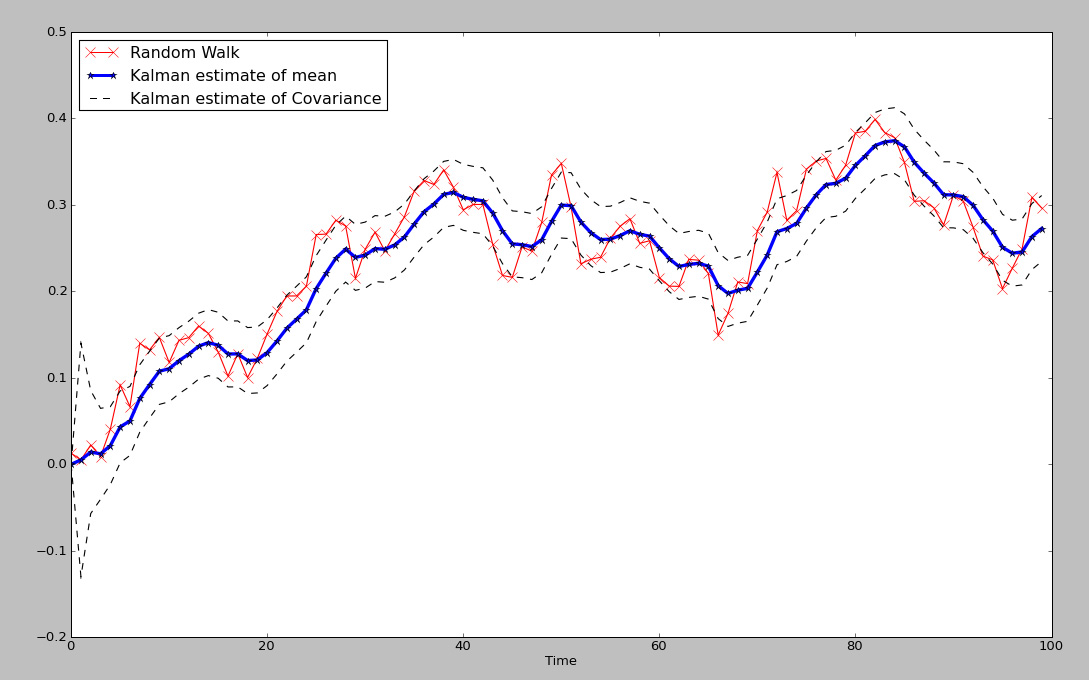
Fig 1. Kalman Filter estimates of mean and covariance of Random Walk
The kf is a fantastic example of an adaptive model, more specifically, a dynamic linear model, that is able to adapt to an ever changing environment. Unlike a simple moving average or FIR that has a fixed set of windowing parameters, the kalman filter constantly updates the information to produce adaptive filtering on the fly. Although there are a few TA based adaptive filters, such as Kaufman Adaptive Moving Average and variations of the exponential moving average; neither captures the optimal estimation of the series in the way that the KF does. In the plot in Fig 1. We have a blue line which represents the estimated dynamic 'average' of the underlying time series, where the red line represents the time series itself, and lastly, the dotted lines represent a scaled covariance estimate of the time series against the estimated average. Notice that unlike many other filters, the estimated average is a very good measure of the 'true' moving center of the time series.
Without diving into too much math, the following is the well known 'state space equation' of the kf:
xt=A*xt-1 + w
zt=H*xt + v
Although these equations are often expressed in state space or matrix representation, making them somewhat complicated to the layman, if you are familiar with simple linear regression it might make more sense.
Let's define the variables:
xt is the hidden variable that is estimated, in this case it represents the best estimate of the dynamic mean or dynamic center of the time series
A is the state transition matrix, or I often think of it as similar to the autoregressive coefficient in an AR model; think of it as Beta in a linear regression here.
w is the noise of the model.
So, we can think of the equation of x=Ax-1 + w as being very similar to the basic linear regression model, which it is. The main difference being that the kf constantly updates the estimates at each iteration in an online fashion. Those familiar with control systems might understand it as a feedback mechanism, that adjusts for error. Since we can not actually 'see' the true dynamic center in the future, only estimate it, we think of x as a 'hidden' variable.
The other equation is linked directly to the first.
zt=H*xt+v
zt is the measured noisy state variable that has a probabilistic relationship to x.
xt we recognize as the estimate of the dynamic center of the time series.
v is the noise of the model.
Again, it is a linear model, but this time the equation contains something we can observe: zt is the value of the time series we are trying to capture and model with respect to xt. More specifically, it is an estimate of the covariance, or co-movement between the observed variable, the time series value, and the estimate of the dynamic variable x. You can also think of the scaled envelope it creates as similar to a standard deviation band that predicts the future variance of the signal with respect to x.
Those familiar with hidden markov models, might recognize the concept of hidden and observed state variables displayed here.
Basically, we start out estimating our guess of the the average and covariance of the hidden series based upon measurements of the observable series, which in this case are simply the normal parameters N(mean, std) used to generate the random walk. From there, the linear matrix equations are used to estimate the values of cov x and x, using linear matrix operations. The key is that once an estimate is made, the value of the covariance of x is then checked against the actual observable time series value, y, and a parameter called K is adjusted to update the prior estimates. Each time K is updated, the value of the estimate of x is updated via:
xt_new_est=xt_est + K*(zt - H*x_est). The value of K generally converges to a stable value, when the underlying series is truly gaussian (as seen in fig 1. during the start of the series, it learns). After a few iterations, the optimal value of K is pretty stable, so the model has learned or adapted to the underlying series.
Some advantages to the kalman filter are that is is predictive and adaptive, as it looks forward with an estimate of the covariance and mean of the time series one step into the future and unlike a Neural Network, it does NOT require stationary data.
Those working on the Neural Network tutorials, hopefully see a big advantage here.
It has a very close to smooth representation of the series, while not requiring peeking into the future.
Disadvantages are that the filter model assumes linear dependencies, and is based upon noise terms that are gaussian generated. As we know, financial markets are not exactly gaussian, since they tend to have fat tails more often than we would expect, non-normal higher moments, and the series exhibit heteroskedasticity clustering. Another more advanced filter that addresses these issues is the particle filter, which uses sampling methods to generate the underlying distribution parameters.
--------------------------------------------------------------------------------
Here are some references which may further help in understanding of the kalman filter.
In addition, there is a kalman smoother in the R package, DLM.
http://www.swarthmore.edu/NatSci/echeeve1/Ref/Kalman/ScalarKalman.html
If you are interested in a Python based approach, I highly recommend the following book...Machine Learning An Algorithmic Perspective
Not only is there a fantastic writeup on hidden markov models and kalman filters, but there is real code you can replicate. It is one of the best practical books on Machine Learning I have come across-- period.
I like your style, but you must admit that building multi-dim models would be a bit tough to explain to others without some 'math jargon' like vectors.
ReplyDeletelee,
ReplyDeleteFirst, nice blog. I'll try to look at it in a bit more detail when I get a moment.
Second, not to knock math, as it's obviously extremely important. It's just that I myself have come across so many obfuscated concepts (like support vector machines, for instance), that could be explained in simple layman terms
with a diagram and a brief summary, for those interested in practical application.
I think there is a such a great proliferation in OS based tools, that this generation can spawn technical quants; much as Engineers have technician counterparts. Often it's not neccessary to understand the mathematical proofs and details in order to gain a simple intuitive grasp and be able to apply it usefully. That was one of my goals in starting this blog.
I discovered your blog recently, excellent work, it is giving me much material for thought and study. Congratulations.
ReplyDeletethanks tradertrib,
ReplyDeleteHope you stick around and learn some new things. And please don't hesitate to give feedback; good and bad.
I have come across a number of recent Internet posts like this that attempt to bring better understanding to what the Kalman filter is, how it is applied and what fields it is used in. Thank you for contributing to this effort.
ReplyDeleteIt is a complicated concept requiring more than a basic understanding of linear algebra and statistics to fully understand the inherent nature of how it truly behaves and how to apply it properly.
I have spent the past several months getting acquainted with Kalman estimation and I think I have a good understanding of basic applications where the state-transition and measurement matrices are linear and the noise is Gaussian in nature. With this in mind, I think the basic equations to process data are straight forward to implement in any programming language. It is the derivation of the process and measurement models that are the key to good understanding of this concept.
If you can take non-linear process and measurement models and derive equivalent linear models and know how to characterize the respective process and measurement noise processes (and know the consequences of these being non-Gaussian), then the application of the Kalman filter/estimator equations is readily done.
Michael.
I have also been familiarizing myself with the Kalman filter, it seems the equations assume an underlying 'model' (for example one paper I looked at had an example of estimating a random constant), what model(s) would one apply to a random walk such as the one in the picture?
ReplyDeletecraig,
ReplyDeleteThe random walk itself was simply generated as a cumsum of normal variates N(x,std). I often use x=.002 and std=.02 as a simple RW proxy for the markets.
Regarding the KF model for the rw, it is the model stated in the equations in the post. xt|xt-1 being the best linear unbiased moving center of the dynamic linear model, and yt|xt being the estimate of the time series or covariance with respect to the estimate xt.
The transition and observation eqs A and H were assumed a constant 1 for the exercise.
The 1st estimates of x0, y0 were simply the normal parameters used to generate the series; ie. .002 and .02, respectively. The update equations take over from the initial estimates.
IT
Of course this is an idealized case. That is using the "true" mean and standard deviation values (0.002 and 0.02, respectively) of the normal Gaussian process as the initial estimates for the Kalman filter or estimator.
ReplyDeleteInitial Kalman estimator values are typically approximated by using a single realization of the process under consideration (assuming ergodicity) or a set of realizations.
There are statistical limits to what a Kalman estimator can deal with. It's hard to summarize these in general terms, these are most often set on a case-by-case basis.
IT - With respect to your random-walk model, how did you arrive at the mean value of 0.002 and standard deviation value of 0.02? And what markets and specific indexes did this work focus on? Thank you.
Michael.
Hi michael,
ReplyDeleteEven though I said I used the exact N(.002,.02) estimates as initial states, I actually used different values to make sure it would still converge to the correct process; in this case it did. Although, I agree it's a bit of a simplistic model; I try to keep the models simple in the blogs for the most part.
When simulating a simple RW, I often use the mean and std values N(.002,.02) just from experience as they are pretty close to major equity indices.
In this toy model, I used cumsum (for simple compounding I use cumproduct of 1+N(u,std)_rtns), but if I was modelling something more accurate, I would
1) Record the mean and std of the actual instrument as a proxy for the RW.
2) If I'm modeling a price series, I will use Geometric Brownian Motion model, which doesn't allow negative price values; and give a lognormal price distribution (for things like terminal wealth monte carlo simulations, for example).
I'm also working with variants of particle filters, which as mentioned, are more flexible in terms of modeling non-normal distribution of innovations.
Hi, I have done a bit of research on the packages you mentioned: dlm for R
ReplyDeleteI thought that the Kalman Filter was causal (not using future values to calculate present mean).
But apparently the one you use (in the dlm package) is not causal. I thought the smoothing was so good that I tried to calculate the estimate mean at different dates.
And... its different!
Can you execute this example and tell me what you think about this magic causal smoothing?
library(dlm)
s <- dlmSmooth(Nile, dlmModPoly(1, dV = 15100, dW = 1470))
Nile2 = ts(Nile2, start=1871, frequency=1)
s2 <- dlmSmooth(Nile2, dlmModPoly(1, dV = 15100, dW = 1470))
plot(Nile, type ='o')
lines(dropFirst(s$s), col = "red")
lines(dropFirst(s2$s), col = "red", lwd=2)
Hi xfm,
ReplyDeleteIt sounds like you are possibly mixing blogs? The causal smoothed filter blog, was not the same as the Kalman Filter blog.
Firstly, I was unable to replicate your experiment exactly as there is no Nile2 time series (at least that I could find). However, if I understood correctly; you can simply copy Nile and change the last value.
What will happen is that final few values will change to reflect the best fit for the entire series. I think this is what you are referring to? If so, I do not typically use dlm (but it looked to be the only package implementing the kalman filter in R), but I assume it is running the entire series in batch mode and then estimating the best fit of the entire series for each of your runs, which changes some of the endpoints.
I actually wrote an online type implementation in Python for my example and as far as I know, do not have this issue; it simply updates each estimate at every new time step. If I get a chance, I'll go back and confirm this for you.
In the mean time, you might look into whether there is an online option for the dlm package estimator.
Hi IntellingTrading,
ReplyDeleteThanks for your answer. Indeed, my mistake, Nile2 was not defined.
Maybe this example will be better:
rm(list=ls())
library(dlm)
s <- dlmSmooth(Nile, dlmModPoly(1, dV = 15100, dW = 1470))
plot(Nile, type ='o')
lines(dropFirst(s$s), col = "red")
causalSmoothedNile = first(Nile, 4)
for (i in 5:length(Nile)) {
Nile2 = ts(first(Nile,i), start=1871, frequency=1)
s2 <- dlmSmooth(Nile2, dlmModPoly(1, dV = 100, dW = 10))
lines(dropFirst(s2$s), col = "red", lwd=1)
causalSmoothedNile = c(causalSmoothedNile, last(dropFirst(s2$s)))
}
causalSmoothedNile = ts(causalSmoothedNile, start=1871, frequency=1)
lines(causalSmoothedNile, col = "orange", lwd=2)
What I do here is just computing the rolling kalman smoothing, ie, giving the algo the time serie Nile cut at each date.
Anyway I thought that this filter was causal, it is not. My mistake. I guess my question is really if the Kalman Filter can give a good real time smoothing. Different from a moving average... Or a FIR.
I have to say I doubt a bit.
After launching the first script, can you try to execute
plot(Nile, type ='o')
lines(causalSmoothedNile, col = "orange", lwd=2)
lines(EMA(Nile,6), col = "green", lwd=2)
The green line is the EMA6 of Nile, and the orange one is the best estimate obtained by the ROLLING Kalman Filter smoothing
What do you call "online" option?
xfm, because I got to first and could not have R recognize the command (don't know what library it came from) first from first(Nile,4) ((Error: could not find function "first")), I decided to abort the mission, before debugging as in the last example. I'm pretty sure your concern is what I mentioned earlier though; that the filter changes with rolling data (particularly at the endpoints), yes? This is correct, although I'm not sure it is strictly causal or not in the sense that causality requires future data.
ReplyDeleteThere are, however, many types of transformations that DO change data with rolling windows, since they find the best smoothed fit to that data window (splines, wavelets, and SVD come to mind).
You can look into online vs. batch training.
To simplify in the sense I was explaining, is that batch typically processes data in parallel (all at once), while online does so sequentially (or one at a time). If you use a rolling window, it is using batch training on overlapping windows each iteration, which can and will alter properties of the transformed data dependent on overlapped regions. If you transform and processes the data only one element at a time (online), you can sometimes avoid these problems.
Lastly, the semi-smoothed property of kalman filtering is just a side benefit, not the major goal.
Cheers,
IT
Thanks for your last explanation.
ReplyDelete1/ last comes from the package xts that I recomend to you. It is used by the quantmod packages and both of them are very useful.
2/ Thanks for the explication of the difference of batch and online. My demo was indeed running a batch computation, meaning I was rolling the window, adding one more data each time. But indeed I suspect we suffer in that case from edge effects.
Thanks for taking time trying to debug! my script. I tried to use as much as possible smple functions but was fooled by first.
Keep the blog alive
Cheers
xfm
"last comes from the package xts" ... would be a good general practice to include require(xts) or library(xts) in your script to make this clear.
ReplyDeleteWhat is H in this equations??
ReplyDeletext=A*xt-1 + w
zt=H*xt + v
And how to calculate it??
romankrd,
ReplyDeleteH is the fitted coefficient of the covariance estimate of the series regressed against the estimated value of the moving center value xt (hat). A derivation should be found on both the references cited at the end of the blog.
IT
Thank you! :)
ReplyDeletehttp://bilgin.esme.org/BitsBytes/KalmanFilterforDummies.aspx
This link can be helpful for dummies like me to understand Kalman filter)))
Intelligent Trading...Thank you for this fantastic post on a useful implementation of a Kalman Filter in R. I looked for it in the comments above and in the initial blog post, but I didn't see any link or posting of the original R code used to produce the image shown above. Is there any chance you may be able to post that or provide a link to it?
ReplyDeleteThanks again as this is a very helpful illustration of the use of the KF functionality.
Hi anon,
ReplyDeleteThe package for kalman filter that I recall is DLM. http://cran.r-project.org/web/packages/dlm/dlm.pdf
I created the above example in Python, however.
There is a similar example in the Marsland book, "Machine Learning," in the recommended book section up top.
cheers,
IT
It was mentioned that the Kalman filter from the dlm package is not causal. Is that true of Kalman filters in general or only the dlm implementation? I'm curious to know whether the fkf, kfas, or sspir implmentations might be causal.
ReplyDeleteKalman filters generally are not dependent upon unseen future data as far as I know. As explained in the basic tutorial, they make estimates and corrections of properties of the data in an online fashion (as it arrives).
ReplyDeleteIT
IT,
ReplyDeleteI have just come across your blog, having recently been exposed to adaptive trading systems following my disappointment with static strategies. I really enjoy your posts, and in particular the way you explain complicated concepts in a simple manner.
I was hoping to ask for advice. Are there any strategies or methods you've come across that you think might be applicable to successfully trading the FX in a 1-hour window? Obviously factors like interest rate differentials won't come into effect in such a short timeframe. I've had some ideas of my own, but I don't want to mention them right now in case they interfere with whatever suggestions you might have for me.
I'm quite able to test these strategies myself, but I would greatly appreciate a push in the right direction.
Cheers,
Jeff
Thanks,for your post, I'm finally getting some decent results with my interpretation of the kalman filter. Its really just a simple recursive way of tracking a linear parameter such as beta based on the volatility of the parameter and the amount of noise in the measurement. If you wanted to also include other inputs such as market depth & volatility to a Beta estimate how could this be added to the kalman filter? A PhD type told me that Beta is highly correlated with variance, (today's high vol stocks -> today's high beta stocks), trying to see how adding various inputs would work with the kalman filter.
ReplyDeleteI wish I hadn't spent the last 12 months staring at matrix formulas in several quant textbooks as the info on the web including your posts are a lot more intuitive!
Hi Jeff,
ReplyDeleteNot certain I fully follow your approach.
I assume you are going to collect some proprietary factors, then use PCA to reduce the factor set. Given such a factor set, you use a kalman filter to update the factor values?
It's possible. As an example, a common model in portfolio modeling is to update the beta parameters dynamically via a kalman filter estimator. The only way to truly know is run the actual experiment and observe how it behaves on forward data.
Cheers,
IT
Jeff,
ReplyDeleteJeff, I apologize as I removed your post (accidentally), but I saved the answer above.
Regarding obvious factors, any form of news updates comes to mind. This will require some translation or utilization of nominal data, however.
IT
scottc,
ReplyDeleteThank you for the kind words. Regarding multivariate modeling, I haven't done too much in this area with respect to the kalman filter. However, there is an R package called KFAS you might want to look into.
http://cran.r-project.org/web/packages/KFAS/index.html
IT
IT,
ReplyDeleteWhat I actually meant is what you described in the second paragraph of your response, ie. updating the Beta parameters of a linear model dynamically by utilising the Kalman filter. If that's already a common occurrence in portfolio modelling, I take comfort in the fact that I seem to be on the right track.
Now all that remains is finding appropriate factors. Thanks for your response.
Cheers,
Jeff
IT,
ReplyDeleteRegarding Kalman filter, how do you model the returns (or do you model the price). Which process do you use? From my understanding, we can't simply plug in the returns without modelling them as an ARMA/ARIMA process, at the least. Does the graph on top show xhat (the posterior) or xhatminus (a priori) forecast.
Thanks for writing this blog!
Peter
Hi Peter,
ReplyDeleteIt's been a long while since I wrote this post and the accompanying code. But generally, we simply enter some actual price series or a rw model, or variant such as arma/arima, we also intialize the algorithm with an estimate of the mean and covariance of the process.
Some of these initial estimates are arrived at via trial and error or having knowledge of the system behavior beforehand.
Blue line is xhat (prior) forecast overlaid with actual series (present) in Red. The Red series in this example is a simple gbm model of a random walk.
IT
Hi, IT
ReplyDeleteOne question about the kalman fiter: How do you estimate the measurement noise R and the process noise Q? Or do you assign a constant to them? Thanks.
anon,
ReplyDeleteOne way I approach it is to start by visualizing the result running sweeps of R and Q values and observing if the response is what I am looking for in the estimator.
I've found in the case of estimating time series as in the example I posted is to use a very small value of process noise Q, relative to the measurement noise, R, as we are looking for a fairly smooth estimate of the process.
IT
Just thought I would make a comment on the 'dlm' package.
ReplyDeleteI believe the function dlmFilter is what xfm was looking for; dlmFilter is causal, while dlmSmooth is not.
thanks K.
ReplyDeletehi,
ReplyDeleteComing back to the question of R & Q. For time series processes should I update R (measurement noise) based on realized volatility calculation to capture the varying volatility dynamics of financial time series? How should I update Q if I do this for this R?
Cheers!
anon,
ReplyDeleteSorry I've been out a few days, but the update will automatically happen in the KF equation updater. You can do many things to adjust and toy around with some variables like the gain factor, K, itself. In the R program DLM, I believe they show examples of how do deal with discrete time jumps and quickly updating based upon the jump size.
All you should have to really do (assuming Gaussian type RW) is set the initial R and Q Values to reasonable sizes and ratios, the rest will work itself out in the update (feedback) process. If is updating too slow or fast, you can try to run sweeps of R, Q sizes, and ratios of meas/process noise to your time series.
IT
Anon from above (should register; excellent website).
ReplyDeleteThanks for your answer. Playing around with KF in Matlab/ R so understand it better. Still not sure about setting the R/Q ratio systematically. Some time series that I am applying KF to are "noisier" than others. They are RW's with some transients on top.
For some financial series I'd want the KF to update quiet fast, while slow for others. Can I invoke any arguments from information theory/ volatility analysis/ autocorrelation to set an optimal R/Q ratio systematically for any given arbitrary RW time series rather than choosing a ratio that "looks" reasonable?
Thanks.
A lot of it is part art, part science. However, you can borrow from machine learning-- various validation and regularization methods to each series. Most of these methods try to generalize and tradeoff between fitted bias and variance vs model complexity.
ReplyDeleteAt the end of the day, you want to best generalize your model to minimize errors on out of sample data. That discussion however, would take a much larger post that I might consider writing some time in the future.
IT
Hey there,
ReplyDeleteI am working on an article and i am mixing Improved particle swarm optimization with KF to get the best result on stock forecasting. i am trying to find out the fitness function but have not been successful yet. have any idea?
Hi mahdi,
ReplyDeleteI don't have a one size fits all function for you. But certainly, you could start out using a very simple RMSE metric. If you have control over fitness, you could try to target some metrics like CAGR, terminal wealth, and sharpe ratio to start.
IT
Dear IT,
Deletethanks for your help. the article is almost done. you are the best
mahdi,
DeleteGlad to hear it. Thanks for letting me know and please let me know if there is any link to the article.
Best,
IT
Have you experimented at all using either the Particle or Unscented version? What I am wondering is how one could can construct a simple price function so to be used in conjunction with either of the non linear versions of the Kalman filter.
ReplyDeleteHi Dave,
ReplyDeleteI have experimented with both, but there aren't many (easy to implement) public packages available to do so. There was a writeup and some code available on TR8DR blog site, some time ago.
IT
yes I saw the sin function version implemented at the blog you mentioned. If one wanted to apply this but to a simple price series what kind of price function could they use? I guess the hardest part here is how do you determine what type of function to use when predicting something like price?
ReplyDeleteHi Dave,
ReplyDeleteSorry for the delay. I appreciate your feedback. Without divulging any proprietary knowledge, I can only concur that that is one of the challenges I worked on for a long time.
There are dozens of econometric models that already exist for this; some have worked for years on some price series.
I will add to your thoughts in that something you might also consider besides just function is to explore what types of predictors might also be useful in price forecasting.
Regards,
IT
Thanks IT. Did you find that the linear version of the filter to be sufficient. Or did you have to move onto variants I.e unfiltered, particle, gaussian process, etc...
ReplyDeleteIT would you be able to do a post (without divulging information) on how one of these predictors could be used?
ReplyDeleteHi Dave,
ReplyDeleteOne of these days I could try to put something together. What I've found regarding the versions, is that using a more sophisticated variant (e.g. particle) does not necessarily help in short term forecasting of trades.
IT
Regarding the discussion of dlmFilter and dlmSmooth in the R DLM package, or the comparable two functions in the pykalman package, I don't don't why causality in the EE sense should recommend itself, particularly in a batch or moving window process. A Rauch-Tung-Striebel smoother (as in dlmSmooth, and sometimes sloppily referred to as a "Kalman smoother") is a Bayesian updater. The idea is that after one has made a forward estimate, as in dlmFilter, and the actual data is observed, it's entirely sensible to go backwards and update the state estimates in light of what was actually observed. Accordingly the filtering-smoothing process has a structure like that of the EM algorithm ("expectation-maximization") where there is a run forward through the dataset, and then backwards doing the state update.
ReplyDeleteBTW, the pykalman package for Python is fine, is even available for Python 3, and handles missing observations like DLM does, but I found it's estimate of the log-likelihood to be broken. Also, it uses a nonlinear optimizer whereas DLM uses the SVD. Accordingly, the DLM is much more numerically stable than pykalman.
I have started a code to implement the logic of DLM in Python, but I had to shelve it. I was hoping to simply translate and then clean up the DLM open source code into Python, but found it difficult to free of decidedly R-ish things. So, this would be a nice thing to do, but I need to design it afresh from the equations, and have not found the time yet.
@Jan
ReplyDeleteThanks for sharing!